Apple odhalil architekturu svých AI modelů a nastínil jakým směrem se ubírá vývoj Apple Intelligence
- Apple rozdělil svůj lokální AI model na dvě části, čímž výrazně snížil nároky na paměť a zrychlil odezvu
- Cloudový model využívá novou architekturu Parallel-Track Mixture-of-Experts, která je efektivnější a modulární
- Podpora vícejazyčných dat vzrostla o 275 %, čímž se významně zlepšila použitelnost mimo angličtinu
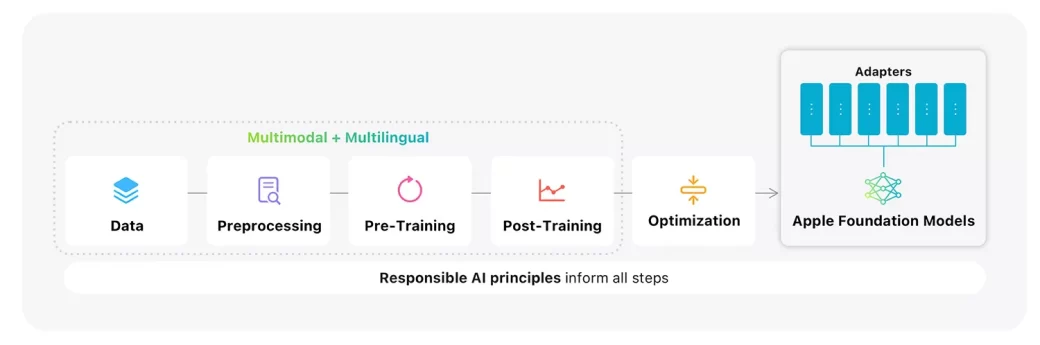
Během vývojářské konference WWDC25 představil Apple nové verze svých základních jazykových modelů pro zařízení i cloud. Nyní společnost zveřejnila technický report s názvem Apple Intelligence Foundation Language Models – Tech Report 2025, který podrobně popisuje architekturu, zdroje dat, trénovací procesy, optimalizace a srovnávací testy. Dokument je určen především pro technicky zaměřené publikum, ale obsahuje řadu zajímavých informací, které stojí za pozornost.
Lokální model rozdělen na dva bloky
Apple už dříve prozradil, že jeho on-device model má přibližně 3 miliardy parametrů. Nyní upřesňuje, že model je rozdělen do dvou bloků:
- Blok 1 obsahuje 62,5 % transformačních vrstev.
- Blok 2 obsahuje zbytek, tedy 37,5 %, ale bez key a value projekcí.
Toto rozdělení vedlo ke snížení paměťových nároků na cache o 37,5 % a stejnému zrychlení při generování prvního tokenu. Apple zároveň uvádí, že tím nedošlo k negativnímu vlivu na kvalitu výstupu modelu.
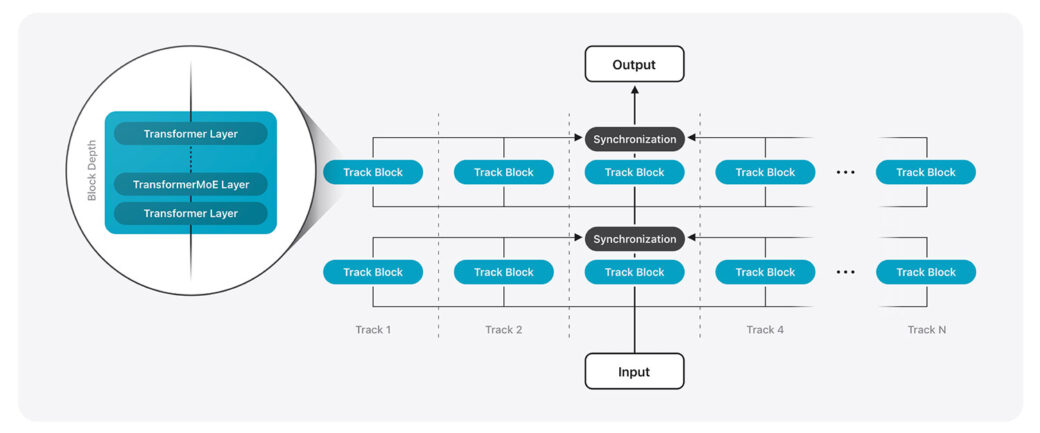
Cloudový model: Architektura Mixture-of-Experts
Cloudová varianta běží na platformě Private Cloud Compute a využívá architekturu nazvanou Parallel-Track Mixture-of-Experts (PT-MoE). Místo jednoho velkého modelu používá Apple sadu specializovaných submodelů (tzv. expertů), které se aktivují jen při relevantních úlohách.
Model je navržen jako Parallel Track Transformer – každý „track“ zpracovává vstupy paralelně a synchronizuje se pouze na určitých místech. Kromě běžných vrstev obsahuje i MoE vrstvy, které aktivují pouze malé množství expertů dle potřeby.
Díky kombinaci globální a lokální pozornosti (Interleaving Global and Local Attention Layers) dosahuje model vysoké efektivity i škálovatelnosti bez ztráty kontextu.
Zlepšená jazyková podpora o 275 %
Jednou z největších kritik vůči Apple Intelligence byla omezená podpora jazyků mimo angličtinu. Apple reagoval zvýšením podílu vícejazyčných dat z 8 % na 30 %. Navíc rozšířil slovník tokenizéru ze 100 000 na 150 000 tokenů.
Modely byly testovány s využitím promptů od rodilých mluvčích a podle Applu dosáhly výrazného zlepšení v přesnosti i přirozenosti odpovědí.
Odkud Apple čerpal trénovací data?
Apple ve zprávě zmiňuje více zdrojů:
- Veřejná webová data: Sběr dat prostřednictvím Applebotu, který respektuje pravidla robots.txt. Data prošla důkladnou filtrací pro odstranění nekvalitního obsahu.
- Licencovaný obsah: Společnost získala obsah od vydavatelství (pravděpodobně Condé Nast, NBC News aj.).
- Syntetická data: Využita pro úlohy jako matematika, kódování či multimodální úlohy. Tato data hrála klíčovou roli v ladění modelů.
- Vizuální data: Apple nasbíral přes 10 miliard párů obrázek-popis, včetně OCR textů a ručně psaných poznámek.
Ačkoliv se o Applu často mluví jako o společnosti, která v oblasti umělé inteligence zaostává, tento report ukazuje, že v zákulisí probíhá intenzivní vývoj. Apple se soustředí na modulární přístup, efektivitu a ochranu soukromí – to jsou oblasti, do kterých se konkurence často nepouští. Výsledkem jsou pokročilé modely, které i přes technické výzvy mohou nabídnout relevantní alternativu k současným AI gigantům.


